Great conversation!
I don’t know if Luhmann’s methods are necessarily worthy of the hero worship they receive. He had some neat approaches and, perhaps partly due to those approaches, he produced a lot of good stuff. (Or so I’m told.) I’d bet, though, that the key reason we talk about Luhmann’s methods for knowledge innovation is that he made it easy for us to talk about them because he had interesting artifacts (the slipbox) and he talked about his system.
I imagine we’d talk about the Oprah method or the Kahneman approach just as much if those folks ever put their “workflows” together in the same nice package Luhmann happened to.
Still, I suppose that that’s a tangent, so I will make these paragraphs <small>…
The key practice that Luhmann engaged in (the one that gets obscured by the focus on the artifacts he used to do this) is the thinking that went into linking each piece of a chain to other parts of the chain. He either got really good at “chunking” knowledge due to this workflow, or he created this workflow because he was really good at chunking knowledge. 


That chunking — that deep, productive reading, questioning, and relating — is the best way to “learn” new concepts (see chapter 4 of Oakley’s A Mind for Numbers for more on this).
Because he did it so systematically and with such discipline, he was truly, deeply engaged in these concepts, which made it easier for him to keep doing it, which made him do it more, which made it easier to keep going… you get it.
The cards and the indexing and so on are all artifacts that facilitated this process, but I think they were secondary to his productivity. The design principle here is to find ways to thoughtfully chunk and relate the pieces of knowledge you’re working with. The tech(nology/nique) you use to do that doesn’t really matter (although there are doubtlessly options that make this easier or distract you from it)!
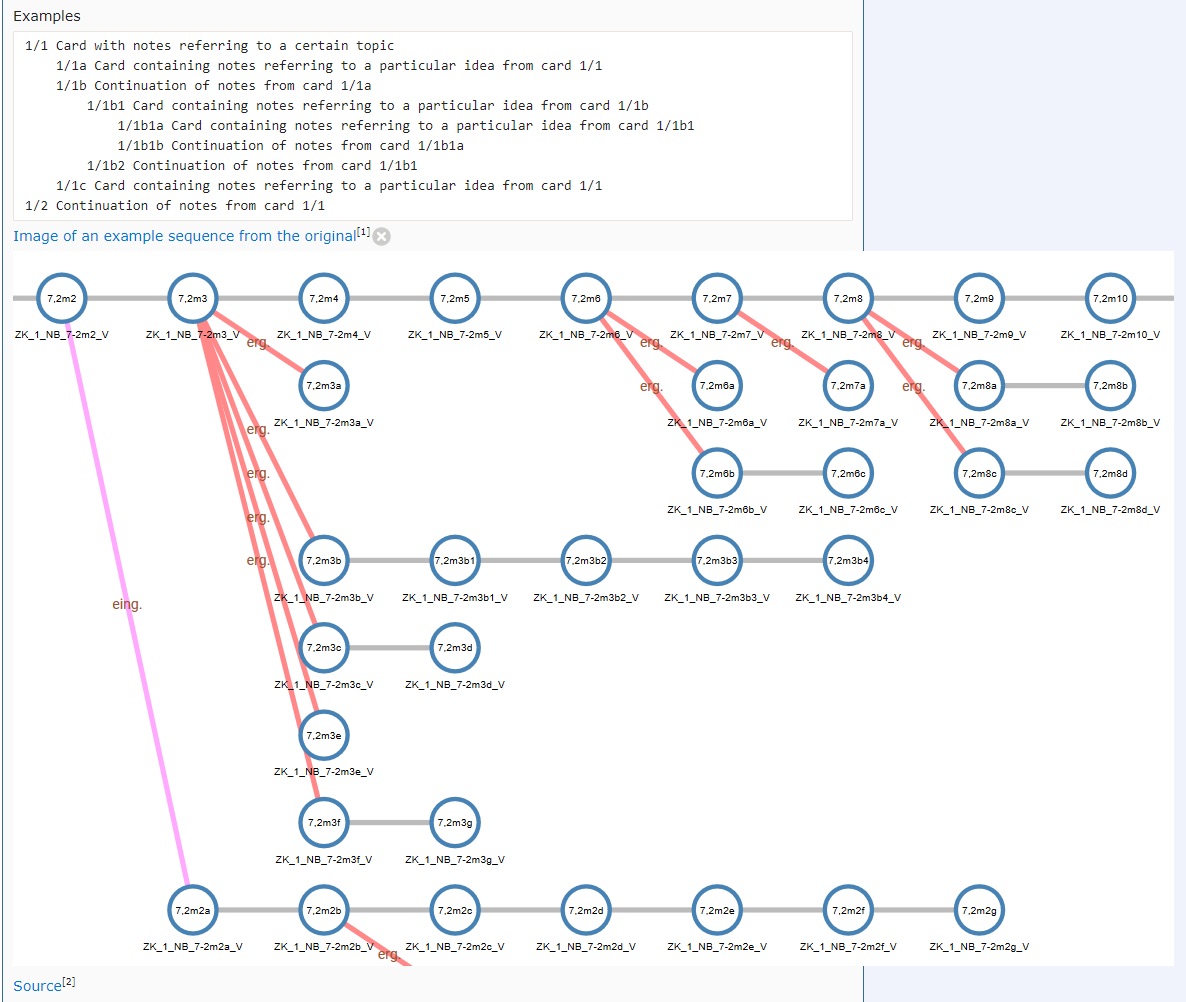
A final point-of-information: graph-wise, the only difference between the two images below is that one is laid out hierarchically while the other has a circular layout. From a graph theory perspective, they’re the same kind of structure: (mostly) acyclic directed graphs.
The first is more sparse than the latter, which could be attributable to the core question of the thread, but that isn’t necessarily the case.
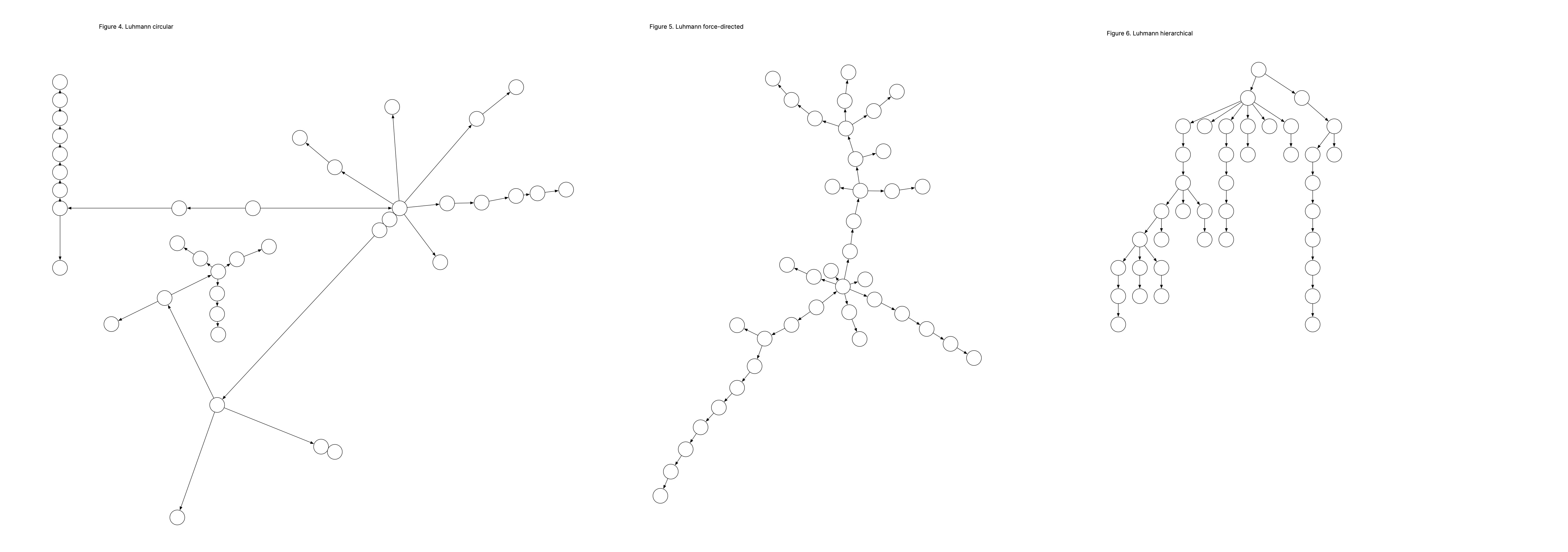
To explore this a bit more, I remade the Luhmann demo graph in OmniGraffle and then reorganized the graph three times using the app’s auto-layout features:
(sorry for the size; doing this quickly and Discourse keeps getting mad at me.  )
)
Again, great conversation. You’ve highlighted a very interesting and potentially valuable tension @JohnAtl!