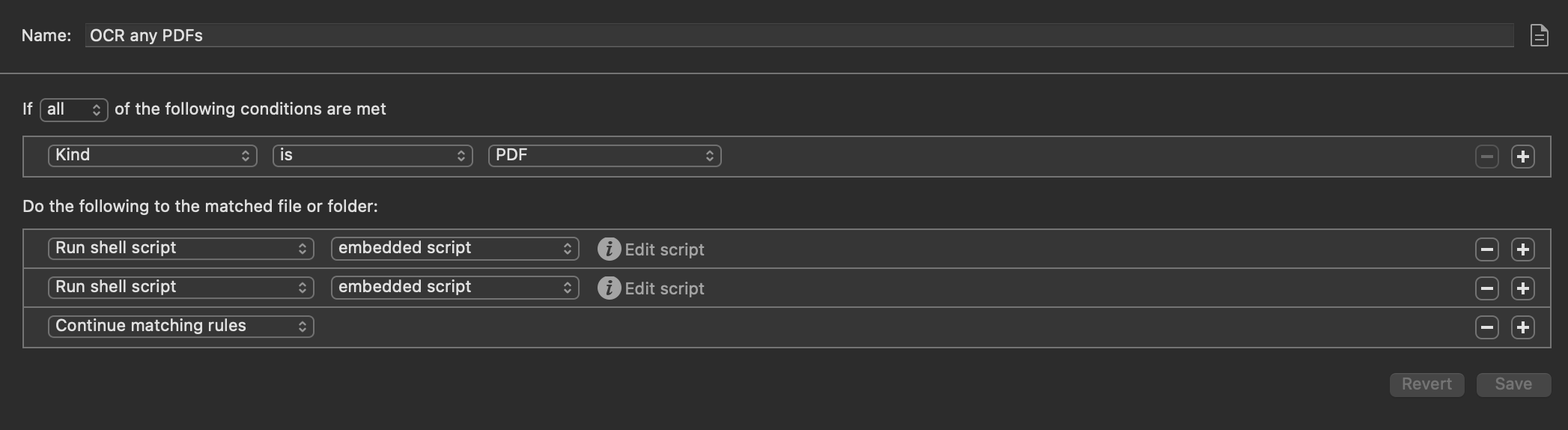
I use PDFpen pro to OCR PDFs using an Apple script that is run from Hazel like has been discussed on this podcast many times in the past. I also use it for creating form fields.
Since nitro bought PDFpen, I am looking to get away from it, however, I am not sure if there is an app that can replace what I am doing. Are there any alternative apps that can use Apple script to OCR PDFs? It would be a bonus if that same app could also create form fields the way that PDF pen does. Those are the only two things that I currently use the app for, are use PDF Expert for everything else.
Why do you want to get away from Nitro, if you don’t mind my asking? I’m in the same boat and weighing my options. So far, the Nitro takeover has not seemed to change much as far as I can tell.
FineReader version 12 was the last one to have Applescript and/or Automator support. At least, to the best of my knowledge. There hasn’t been any mention that it has been brought back.
Besides being the best ocr engine available on the Mac, ABBYY is also the company that has the worst support on the planet. Like basically no support at all.
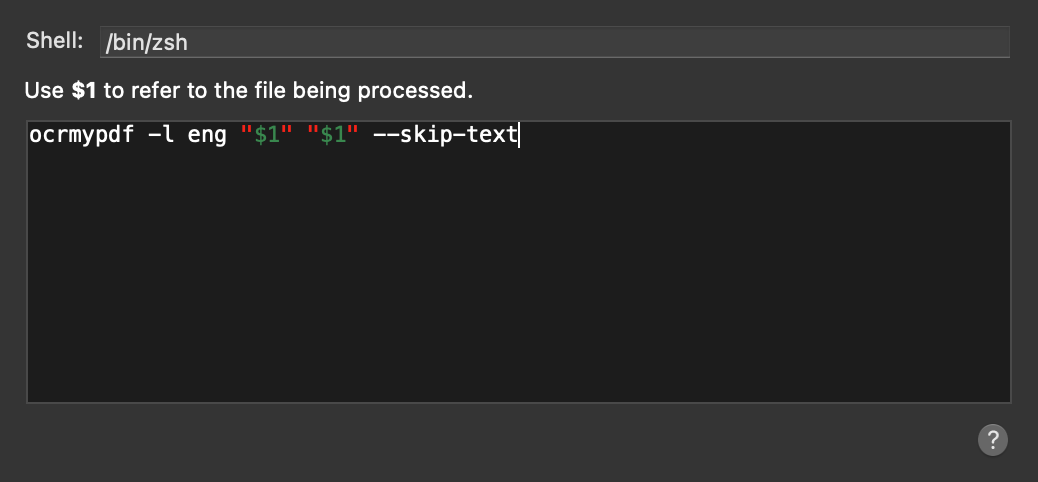
I’m still using version 12. If that stops working I’ll switch to Tesseract and ocrmypdf. Available via homebrew.
I really wasn’t overly happy with PDFPen, it always seemed glitchy and I have just had issues with it. I really like PDFExpert, but it doesn’t seem to have scripting support.
I am not great with shell commands, but if you could point me in the right direction on how to install that and add it into hazel I would greatly appreciate it!
The second script is just a sleep command that I must have put in to debug at some point. You can ignore that.
Then once the PDF has been OCRed, I run other Hazel rules on it to look for embedded text and perform actions. For example, for receipts I save when paying my credit card: