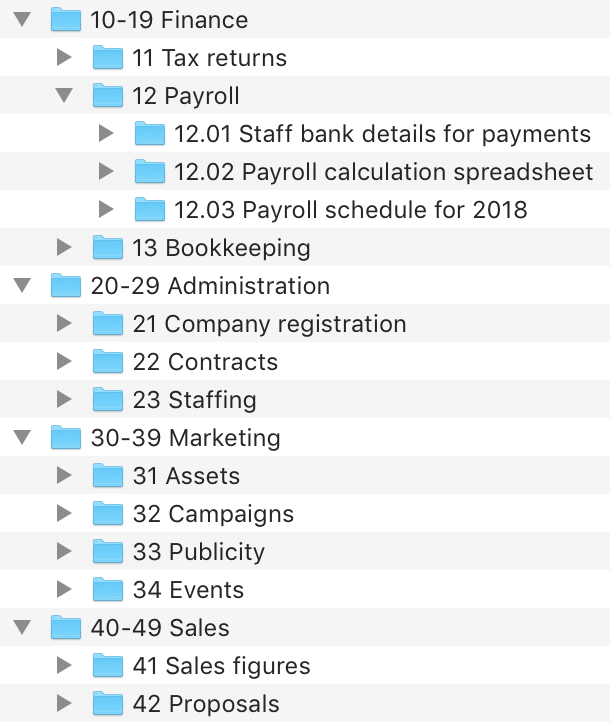
In a recent thread, someone mentioned the Johnny Decimal (johnny.decimal or JD, http://johnnydecimal.com) system, which I have looked at several times in the past, which of course got me to thinking once again about file system organization.a
For those who have not ready about the JD system, in (very) brief, the idea is to break up your files/data into up to 10 major “areas”, and in each area you can have up to 10 “categories”. You assign a number to each category within it’s area, with an are comprising 10 consecutive two digit numbers. For example, if I had an area called “Finances” I might assign it numbers 10-19. Within that, I could have a category called “Bank Accounts” with a category number of 10. I would then have a folder called “10 Bank Accounts”. In that folder I could have up to 99 folders, presumably for each bank, numbered consecutively, starting at 01, so they sort in numbers all order. The folders are named with the category and then item number, so I could have a folder called “10.01 My Bank” as an example.
The idea is that all of the categories under Finances, starting with a two digit number between 10 and 19, sit under the 10 Finances folder, and all of the folders starting with 10, 11, …, 19 sit under an area folder called 10-19 Finances, for organizational purpose.
The net effect is that I always know I can find my My Bank folder by looking for 10.01.
Inside that folder I would have all files related to that bank account.
It seems like this is a potentially effective method of organization, and I wonder if anyone else is using it, and if so, how is it working for you? Have you made any modifications to the way you implement this system?
One nice effect, I think, of this system is that the author of this system suggests that when one creates notes in another app (he likes SimpleNote and nvAlt, but this could apply to notes in Apple Notes, Obsidian, etc) is that he prefixes the title of the note with the appropriate JD number. So, for example, if I created a note about My Bank in Apple Notes, instead of titling it “Stuff about My Bank” I would title it “10.01 Stuff about My Bank.” This allows any form of searching, that that app, or in Spotlight, to easily find stuff anywhere about this topic. He also embeds these numbers in email subjects, and so forth.
In looking at my own data, three additional modifications come to mind.
Firstly, I think that having up to 10 distinct areas would probably we sufficient for me. I also think that writhing a category, say Bank Accounts, having up to 99 (it is proposed that 00 be used for meta data about the category, leaving 01-99 for individual items) would likely be enough for virtually any area of interest as well. (In fact, the point is made that if you have more than 99 folders in a category, the category is probably too broad and should be split into multiple categories.)
I am not convinced that 10 categories in an area is sufficient, however, Just looking at my own Finances, folder, there are more than 10 subfolders. Expanding to three digits is certainly one option, so I could have an area called 100-199 Finances and have up to 100 categories…although admittedly the two digit.two digit format of the JD system is much easily to hold in your head than three digits.two digits, and while I can conceive be of needing more than 10 categories in an area, I doubt I will come close to needing 100.
Yes, it would be possible to for example allocate 25 categories to an area, making the Finances area 100-125, and then another area, say Research be 126-150, and so forth, but I think that the idea that call categories whose first digit is 1 are in the same area is conceptually helpful and that gets lost in the latter scheme.
Areas could be letters of the alphabet, giving up to 26 areas, so Finances would be letter “A”, with Bank Accounts being category 01, so we have a folder called “A01 Bank Accounts” and My Bank is folder “A01.01 My Bank”, so now I have 26 areas each of which can have 99 categories, and in each category 100 items…but the mixing of letters and numbers might provide confusing compared with having 10 areas each of which gets up to 99 categories by using three digits…but maybe using a letter for the area creates a better conceptual organization.
Secondly, within each folder (for example 10.01 My Bank - in the above scenario, 10-19 is Fiancers and 10 is the Bank Accounts category, known to be in the Finance area by its first digit of 1, or it might be A01.01 My Bank, because A is the Finances area, and A01 is the Bank Accounts folder in that area [aside: maybe another separator: A.01.01 means Finances area, category bank accounts, folder for My Bank…], the idea is to just create the files which are needed.
I generally create files prefixed with a date formatted as yyyy.mmdd so that when sorted alphanumerically they are also in date order, although this only applies to some areas such as archived bank statements.
I was thinking it might be helpful to have all files numbered sequentially, starting with perhaps a three digit number, and whenever a new file is placed into a folder it gets assigned a number, so files order in the order in which they were created or added to the folder. This is similar to something I read in blog post by Stephen Wolfram, in which when doing work on a topic he just names his working documents with sequential numbers in the folder.
This would be easy to do with a Hazel rule, but I worry about have Hazel monitoring what could be a huge number of folders in this way…what would be the system overhead?
Finally, I have thought about tagging every file with a month and date tag. Often I remember that I was working on something around July 2022 but not the exact date or where I put the file, so using Spotlight to find files with tags of “July” and “2022” would help locate things…again I don’t want to rely on myself to manual tag files, I don’t want to have Hazel watching every folder….but it would not necessarily be hard to daily scan my documents tree and tag all files as needed.
So, stream of consciousness musing on file organization, If you have read this far, I would be very interesting in thoughts and comments.